怎么禁止搜索引擎抓取某一个页面,例如:链接跳转提示页面(robots.txt规则)
我这段时间总看到搜索引擎抓我/goto的跳转提示页面。
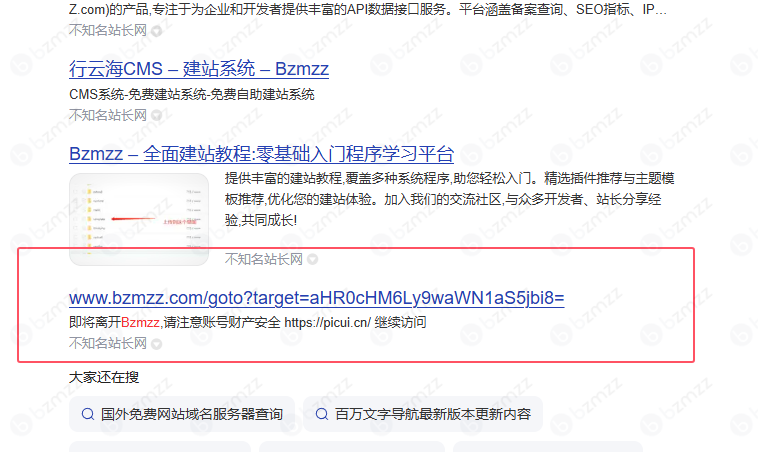
这样网站没有什么好处。这看似不起眼的情况,其实藏着两个不容忽视的问题。
(1)这可能会让搜索引擎觉得咱们网站内容质量不高。要知道,搜索引擎收录页面是希望给用户提供有价值的内容。但 /goto 跳转页大多是引导用户跳转的过渡页面,并且还没有任何内容信息,用户不会点击。导致降低排名,搜索引擎就可能认为这些内容没啥用,甚至觉得整个网站的内容质量都不咋地,这样一来,网站在搜索结果中的排名可能就会受到影响。
(2)频繁抓取跳转页会让搜索引擎蜘蛛的抓取速度变慢。搜索引擎蜘蛛的抓取资源是有限的,它忙着抓取这些跳转提示页面,就会耽误抓取网站里真正有价值的内容页面。这就好比本来蜘蛛能快速把网站的新内容、重要内容都 “看” 一遍,现在却被大量的跳转页绊住了脚,抓取效率降低,网站内容更新后被收录的速度也会跟着变慢。
操作方法:
进入网站根目录 创建文件:robots.txt(添加规则,禁止搜索引擎爬取特定页面。)
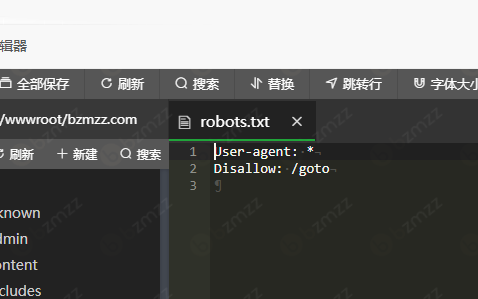
User-agent: *
Disallow: /goto
保存即可。
其他常用规则分享
除了在 robots.txt 中使用 Disallow: /goto 来阻止搜索引擎抓取特定页面外,以下是一些常用的 robots.txt 规则,可帮助站长更灵活地控制搜索引擎的爬取行为。这些规则基于通用实践,适用于 WordPress 或其他网站管理场景,确保真实性和实用性:
- 阻止特定文件类型
禁止爬取某些文件类型(如 PDF、图片或脚本文件),以降低服务器负载或保护敏感内容。例如:User-agent: * Disallow: /*.pdf$ Disallow: /*.jpg$ Disallow: /*.js$这会阻止以 .pdf、.jpg 或 .js 结尾的文件被抓取。
- 阻止特定目录
禁止爬取整个目录,如管理后台或缓存文件夹。例如:User-agent: * Disallow: /wp-admin/ Disallow: /cache/ Disallow: /tmp/对于 WordPress 站点,Disallow: /wp-admin/ 是常用规则,防止抓取管理后台(可允许 /wp-admin/admin-ajax.php 支持 AJAX 功能)。
- 阻止动态参数页面
针对带查询参数的动态 URL,可禁止特定参数模式。例如:User-agent: * Disallow: /*?*sort= Disallow: /*?*filter=这适合电商或筛选页面,防止抓取重复内容。
- 阻止特定爬虫
若只想限制某些搜索引擎(如百度),可针对特定 User-agent 设置。例如:User-agent: Baiduspider Disallow: /private/这仅阻止百度爬虫访问 /private/ 目录。
- 允许特定路径
在 Disallow 后可用 Allow 指定例外。例如:User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php这允许爬虫访问 AJAX 文件,同时阻止其他 /wp-admin/ 路径。
- 阻止爬取整个站点
若需完全阻止搜索引擎抓取(如测试站点):User-agent: * Disallow: / - 添加 Sitemap 指引
指定 Sitemap 位置,帮助搜索引擎发现重要页面。例如:Sitemap: https://www.bzmzz.com/sitemap.xml通常放在 robots.txt 末尾。
- 设置爬取延迟
为减轻服务器压力,可设置爬虫访问间隔(秒)。例如:User-agent: * Crawl-delay: 10这要求爬虫每 10 秒访问一次页面。
(本文结束)在Bzmzz.com可以学习到更多的程序安装、使用教程还有实用的工具和插件。我们下期见。
